Airflow and Snowflake¶
In business, data is usually related to business, enterprise prospects, and financial status. Effective data management can help decision-makers quickly and efficiently analyze valuable information from large amounts of data. Data Integration is a very important part of the entire data management process. This article mainly introduces how to use ELT (extract, load, transform) to realize data integration.
Next, we will focus on the basics of ELT and how it can be leveraged in data warehousing to streamline data analysis. We will provide a brief overview of the tools and technologies that are used in ELT, and demonstrate how they can be used to carry out straightforward analysis requirements.
DEMO¶
Background¶
The specific requirement is to save the original movie box office data to the data warehouse and then analyze the original data to obtain relevant results and save them in the data warehouse, used by data analytics teams to help them predict future revenue.
Technology¶

The demo implements the functionality using the following tech stack:
- Data Warehouse: Snowflake
- Extract:
- Tech: N/A
- Reason: The example will skip this phase and begin with the step where data is loaded into the warehouse because the choice of tech stack for extracting data from the source database relies on the type of original database and the deployment platform.
- Load:
- Tech: Using an External Table that Snowflake provides, copy data from S3 to Snowflake.
- Reason: Choosing Snowflake External Table in the contemporary microservice architecture makes it simpler to load data from numerous databases housed on various platforms to the same data warehouse.
- Transform:
- Tech: Create a DBT project to analyze the data, and then store the results in another Snowflake schema.
- Reason: Reusing the existing DBT infrastructure, in this case, is a sensible decision because the output could only be produced using SQL due to the current simplicity of the analytics requirement. It is typically necessary to build code to analyze data for more complex requirements.
- Orchestrator:
- Tech: Trigger DBT projects scheduled by Airflow.
- Reason: Airflow has richer monitoring data and a friendlier UI than Oozie.
Tools¶
Snowflake: data storage¶
Snowflake is a data platform that combines a completely new SQL query engine with an innovative architecture natively designed for the cloud. It enables faster and more flexible data storage, processing, and analysis.
Permission Management
For safety, the best practice recommends using "user" and "role" to control more specific permissions.
Create the role TRANSFORMER in the demo, give it some rights, and give it to the new user:

The WAREHOUSE mentioned above is a concept in Snowflake that’s a collection of computing resources that provides the capability to execute SQL.
Loading
The tool we used to load source data to the warehouse is the stage, which is an intermediate space provided by Snowflake where we can upload the files so that we can use COPY command to load or unload tables.
In the following diagram, MY_S3_STAGE is used to upload data into S3 in our demo:

There are some other database objects in the schema, such as Tables and Views. Also, each database could have several schemas. Based on common practices, we create the schemas RAW and ANALYTICS in the database for persisting source data and processed data, respectively.
DBT (data build tool): Transform source data¶
DBT is a good tool here to transform data using select statements. Based on source data, DBT assists in the demo's collection of historical box office information.
Model
A model is a select statement; models are normally defined in the model's directory in.sql files. There should be at least one model in any DBT project.
The method used to reference the source data is shown in the sample screenshot that follows the sentence. The source table could be declared in the .yml configuration file before using the source() function.

Materializations
In the above example, the model will be constructed as a table on each run using a create table command because there is an in-file setting. Materialization is one attribute to change the strategy for persisting DBT models in warehouses. I have talked more about this in another article.
Test
Sometimes the source data may not match the expectation such as dirty data, in order to guarantee the accuracy of the report, tests can be introduced here.
DBT provides tests on two levels:
- Generic test: This is a kind of test that can be reused again and again at the column level. In the demo, the ticket_year in the source table should be unique and not null:
- Singular Test: This kind of test is a SQL statement to query failed rows which are saved to a .sql file within the test directory. The singular test in the demo is to query the records that total_box_office less than 0, when the test return null means it passes:
Airflow: Tasks Orchestration¶
How can we orchestrate them and make the transform task run regularly once the raw data has been imported into the data warehouse?
Airflow is a platform to programmatically author, schedule, and monitor workflows.
In the demonstration, the tasks are orchestrated using Airflow, the scheduled data is loaded, and a DBT project is triggered to process them.
DAG
The first step is to create a DAG. A DAG(Directed Acyclic Graph) can be considered a pipeline. Some attributes, including name, interval, and start date, are required. Airflow pipelines are configured as code(Python), so it is very dynamic.
In the demo, just set the start date for the DAG to May 20, 2022, and set the interval to daily, which means the DAG will run once per day:
Task
The final stage in explaining a DAG is to add certain jobs to it that are similar to the CD pipeline steps.
A task is the basic unit of execution in Airflow, and usually, one DAG contains multiple tasks.There are four tasks in the demonstration: building a table, transferring data from S3 to Snowflake, carrying out tests, and altering source data.
The purpose of the following task is to create a table in Snowflake; when clarifying this task, just need to provide certain crucial information such as the connection to the SnowflakeOperator:

Execution ModeAirflow will run all the tasks parallelly by default, so if there is a requirement for the execution sequence of tasks, it had better clarify the dependencies between tasks.
In the demonstration, we test the source table first, and only when all the tests are successful do we transform the data.
As shown in the figure below, a failed test will block the task to transform data:
If multiple tasks are expected to run simultaneously, could configure the type of Executor and increase the value of parallelism in the configuration file due to the default Sequential Executor supports running only one task at a time. Finally, declare the relationship for tasks to run parallel as follows:
When the DAG runs, task_2 and task_3 can run concurrently.
Backfill
Assume that one day, we add one more field in the source table due to requirement changes, and we want to re-upload the data for the past 3 months. In this case, we could use catchup in Airflow to backfill all the DAG runs in the past 3 months at once.
In the demo, the start date for the DAG run is 20th May, so when the DAG starts, Airflow will backfill all the DAG runs after the start date is settled:

Monitoring and Debug
Airflow provides a friendly UI that makes it easier to monitor and debug DAG runs:

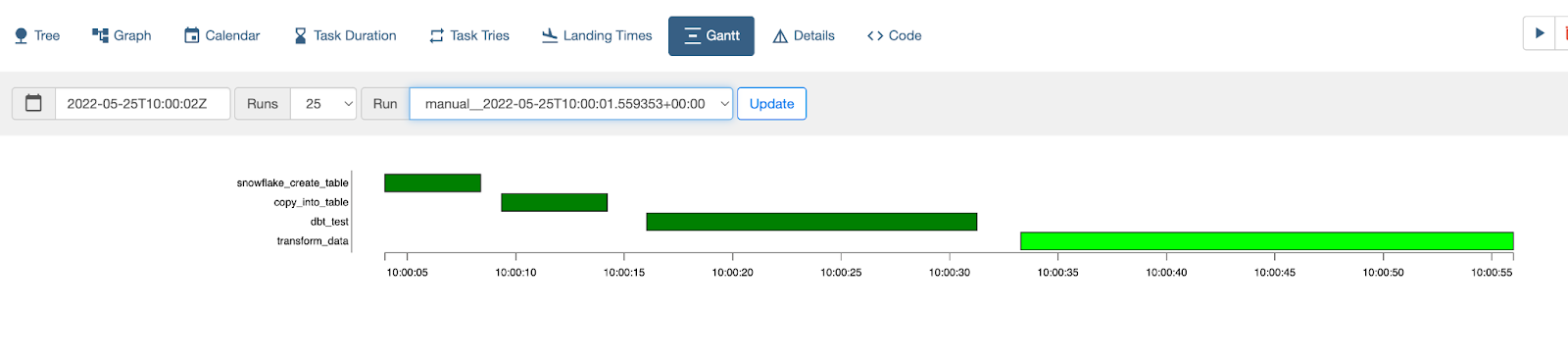

The DAG runs for the whole year The time used by each task to run The log for the task
Here are just a few of all the dashboards, so you can explore them if you're interested.
DEMO Result¶
The source data has been loaded to RAW schema in Snowflake, and the transform job could refer to these data whenever it wants:

Also, since the transform job has persisted the result to the ANALYTICS schema, if there is another analytical requirement in the future, you could use this transformed data directly:

Repo link¶
DBT project: https://github.com/littlepainterdao/dbt_development
Airflow: https://github.com/littlepainterdao/airflow
Hope you can make a basic understanding of Airflow, Snowflake, and DBT via this basic article.